8.1 - Méthode “Diviser pour régner”
1. Le principe
La méthode “diviser pour régner” (divide and conquer en anglais) est une stratégie algorithmique qui se décompose en trois étapes :
- Diviser : décomposer le problème initial en sous-problèmes de même nature, mais de taille plus petite.
- Régner : résoudre chaque sous-problème, en général récursivement, jusqu’à atteindre un cas de base trivial.
- Combiner : fusionner les solutions des sous-problèmes pour construire la solution du problème initial.
Nous avons déjà rencontré cette stratégie :
- Recherche dichotomique dans un tableau trié (vue en première et en mathématiques) : on divise l’espace de recherche par 2 à chaque étape.
- Recherche dans un ABR (arbre binaire de recherche) : à chaque nœud, on élimine un sous-arbre, ce qui s’apparente à une dichotomie.
2. Le tri fusion
Le tri fusion (merge sort) est un algorithme de tri qui applique la méthode “diviser pour régner” :
- Diviser : couper la liste en deux moitiés.
- Régner : trier récursivement chaque moitié.
- Combiner : fusionner les deux moitiés triées en une seule liste triée.
Voici une description de cet algorithme en pseudo-code :
fonction tri_fusion(liste : tableau d'entiers) -> tableau d'entiers
si longueur(liste) <= 1
retourner liste
sinon
milieu = longueur(liste) / 2
liste_gauche = tri_fusion(liste[1...milieu])
liste_droite = tri_fusion(liste[milieu+1...longueur(liste)])
retourner fusionner(liste_gauche, liste_droite)
fonction fusionner(liste_gauche : tableau d'entiers, liste_droite : tableau d'entiers) -> tableau d'entiers
i = 0
j = 0
liste_fus = []
// Fusionner en comparant les éléments de chaque liste
tant que i < longueur(liste_gauche) et j < longueur(liste_droite)
si liste_gauche[i] <= liste_droite[j]
ajouter liste_gauche[i] à liste_fus
i = i + 1
sinon
ajouter liste_droite[j] à liste_fus
j = j + 1
// Copier les éléments restants de liste_gauche (s'il y en a)
tant que i < longueur(liste_gauche)
ajouter liste_gauche[i] à liste_fus
i = i + 1
// Copier les éléments restants de liste_droite (s'il y en a)
tant que j < longueur(liste_droite)
ajouter liste_droite[j] à liste_fus
j = j + 1
retourner liste_fusDérouler à la main l’exécution de cet algorithme avec la liste [5, 2, 4, 6, 1, 3]. Présenter ce déroulement sous forme d’un arbre.
Implémentation en Python :
def tri_fusion(liste):
if len(liste) <= 1:
return liste
else:
milieu = len(liste) // 2
liste_gauche = tri_fusion(liste[:milieu])
liste_droite = tri_fusion(liste[milieu:])
return fusionner(liste_gauche, liste_droite)
def fusionner(liste_gauche, liste_droite):
i = 0
j = 0
liste_fus = []
# Fusionner en comparant les éléments de chaque liste
while i < len(liste_gauche) and j < len(liste_droite):
if liste_gauche[i] <= liste_droite[j]:
liste_fus.append(liste_gauche[i])
i += 1
else:
liste_fus.append(liste_droite[j])
j += 1
# Copier les éléments restants
while i < len(liste_gauche):
liste_fus.append(liste_gauche[i])
i += 1
while j < len(liste_droite):
liste_fus.append(liste_droite[j])
j += 1
return liste_fusTest du programme en console :
>>> liste = [5, 2, 4, 6, 1, 3]
>>> liste_triee = tri_fusion(liste)
>>> print(liste_triee)
[1, 2, 3, 4, 5, 6]Visualisation de l’exécution avec Python Tutor :
Complexité de l’algorithme
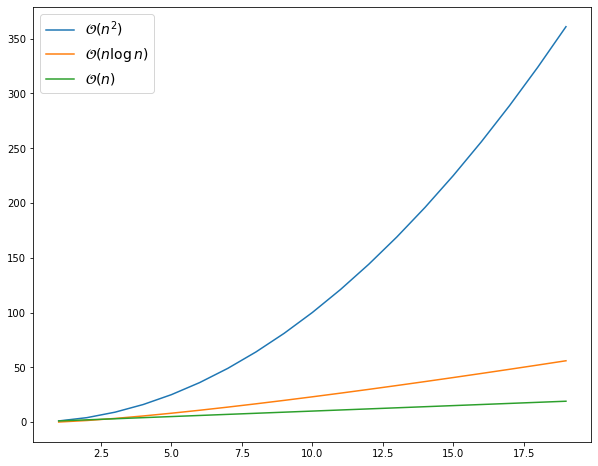
À chaque appel récursif, la liste est coupée en deux. Il y a donc \(\log_2 n\) niveaux de récursion. À chaque niveau, l’ensemble des fusions parcourt tous les éléments de la liste, ce qui représente un travail en \(\mathcal{O}(n)\) par niveau.
Le coût total est donc :
La complexité (temporelle) de l’algorithme de tri fusion est en \(\mathcal{O}(n\log n)\), où \(n\) est la taille de la liste à trier.
Il s’agit donc d’une complexité quasi-linéaire.
Pour comparaison, les algorithmes de tri étudiés en première (tri par insertion et tri par sélection) ont une complexité quadratique \(\mathcal{O}(n^2)\) dans le pire des cas. Le tri fusion est donc beaucoup plus efficace pour de grandes listes.